以免被算力“鎖死” AI進化急需革命性算法
“深度學習所需的大規模樣本數據對于算力產生巨大需求,但近日美國麻省理工學院等研究機構的報告顯示,深度學習正在逼近算力極限,而提升算力所需的硬件、成本和對于環境的影響正變得越來越難以承受……”
美國麻省理工學院、安德伍德國際學院和巴西利亞大學的研究人員在最近的一項研究中發現,深度學習的進步強烈地依賴于計算的增長。其結論顯示,訓練模型的進步取決于算力的大幅提高,具體來說,計算能力提高10倍相當于3年的算法改進成果。大量數據和算力是促進人工智能發展的重要因素,但是研究人員認為,深度學習正在逼近算力極限。換言之,算力提高的背后,其實現目標所隱含的計算需求——硬件、環境和金錢等成本將變得無法承受。
研究人員表示,深度學習急需革命性的算法才能讓AI更有效地學習,并越來越像人類。那么,為何深度學習算法十分依賴算力的增長,現在算力的極限在哪里,如何突破?除了算力,深度學習還能否依靠其他方式改進算法性能?革命性算法的標準是什么?
大規模樣本數據催生計算需求
“深度學習本質上是基于統計的科學,所以大規模的樣本數據對于深度學習的效果至關重要。更大規模和更復雜的神經網絡模型已經被證明非常有效,并在產品中有廣泛的使用,同時這也讓深度學習對計算能力有著更大要求和消耗。”遠望智庫AI事業部部長、圖靈機器人首席戰略官譚茗洲表示。
人工智能設計之初,并沒有考慮節能原則,只要有足夠的算力和電力,算法就可以一直跑下去。
2019年6月,美國馬薩諸塞州大學阿默斯特分校的一份報告顯示,訓練和搜索某種模型所需的電量涉及約626000磅二氧化碳排放量,這相當于美國普通汽車使用壽命內排放量的近5倍。此外,優越的靈活性使深度學習可以很好地建立不同的模型,超越專家的模型,但也帶來昂貴的算力成本。深度學習需要的硬件負擔和計算次數,背后消耗的是巨額資金。
一份業內報告顯示,華盛頓大學的Grover假新聞檢測模型兩周內培訓費用約為25000美元。另據報道,著名人工智能非營利組織OpenAI花費高達1200萬美元訓練其GPT-3語言模型,而GPT-2語言模型,每小時訓練花費則達到256美元。
改進算法降低對計算平臺要求
實際上,算力一直在提高。OpenAI一項研究表明,自2012年以來,每16個月將AI模型訓練到ImageNet(一個用于視覺對象識別軟件研究的大型可視化數據庫)圖像分類中,相同性能模型所需的計算量就減少了一半;谷歌的Transformer架構超越了其之前開發的seq2架構,計算量減少了61倍;DeepMind的AlphaZero與該系統的前身AlphaGoZero的改進版本相匹配,其計算量也減少了8倍。
有網友提出,現在的硬件算力提升有些誤區,不一定非得在單位面積上堆更多的晶體管,我們需要更好的框架來支持底層計算條件及相應的硬件改進。理想情況下,用消費級的GPU就能運行很多深度模型。
“人們對深度學習的性能或結果的要求越來越高,隨之對于算力的需求也越來越大。要讓算力增長或突破,從算法層面,首先可以優化并行計算,有效利用多機多核的計算能力,靈活滿足各種需求。同時,相對于傳統的基于單機編寫的程序,如果改寫為多機多核的并行程序,能夠充分利用其CPU和GPU(或AI芯片)的資源,將使運行效率大幅度提升。”西安電子科技大學電子工程學院教授吳家驥表示。
除了算力,深度學習本身還可通過哪些方式改進算法?吳家驥介紹,深度學習都是在異構硬件上運行,大數據進入時,需要分流處理,從算法上來看,可以調度優化,讓異構架構(CPU、GPU、AI芯片)因地制宜地調度深度學習和大數據處理業務。
吳家驥指出,未來可能很長一段時間內,對深度算法的改進,不僅要從架構、硬件上考慮,還要考慮模型的壓縮能力。例如,就具體問題而言,考慮如何把大象關進冰箱,但問題是冰箱關不了大象,但若把大象壓縮成小貓小狗的大小,就可裝入冰箱。這就需要模型壓縮,在保證精度的前提下,壓縮神經網絡模型,降低對計算平臺的要求,大大提高計算效率,滿足更多的實際場景需求。
研究人員認為,在算法水平上進行深度學習改進已有先例。例如谷歌的張量處理單元,現場可編程門陣列和專用集成電路,并試圖通過網絡壓縮和加速技術來降低計算復雜性。他們還引用了神經體系結構搜索和元學習,查找在一類問題上保持良好性能的體系結構,以此作為計算上有效改進算法的途徑。
算力增長未必會讓AI擁有類人智力
無疑,算法突破的目的是讓機器更像人類大腦一樣具有神經元的功能。但就功耗而言,大腦要像超級計算機那樣運算,自身溫度就會飆升上百攝氏度,所以若簡單認為更多的計算能力就可讓人工智能擁有人類智能的想法顯然是存在爭議的。
“人類的智能中基因與常識是機器所不具備的,其中基因是不需要計算的,常識是可以通過簡單計算實現的。”譚茗洲指出。
“常識決定了基本能力、發現力和創造力,而具有常識能力,是更先進意義上的人工智能。革命性的算法,就是要讓AI具備擁有學習常識的能力,這也是未來一個很有潛力的研究方向。”吳家驥說。
有人說,深度學習大多數是“煉金術”,大多數算法是對經驗更樸實的歸納,對說的問題進行更精辟的演繹。譚茗洲說:“現在數據非常多,算力也在增強,人們依賴深度學習提升AI智力,但‘傻學硬練’形成更強的學習方法,很難達到或超越人類的算力及智力。”
那么,革命性算法的標準是什么,為什么優于深度學習的算法遲遲沒出現?
譚茗洲認為,革命算法的標準首先是在不同場景具有高適應度,可以形成知識記憶和經驗記憶的算法,并且低耗能低成本。未來革命性算法有可能基于三點提升,一是基于常識推理。由于我們面對的大量場景不是通過大量數據訓練而來,人類大腦面對這些場景往往是通過常識推理運算而得出結論,而深度學習并沒有建立這套體系。另外,常識和常識之間的關聯性,加速了人類對結果的推理速度。二是基于負性小樣本的學習。在深度學習模型中,往往很少去學習什么是錯誤的,而汲取負面行為及教訓性質類型的小樣本是有學習意義的。三是基于交流、溝通的學習,人與人交流在學習中分幾個層次,看、聽、模仿等,AI也應多從這幾個方面入手,建立以交通、溝通為目的的學習,而不是單單通過大數據訓練模仿人類智能。
圖片
-
 22省份一季度GDP出爐:廣東
22省份一季度GDP出爐:廣東  河南永城通報代王樓村改廁問
河南永城通報代王樓村改廁問  貢嘎山腳下的村民自發組隊四
貢嘎山腳下的村民自發組隊四
-
 河南太康:打造“紅色引擎
河南太康:打造“紅色引擎  河南太康:智造品牌 打造千
河南太康:智造品牌 打造千  80多個國家爭先搶購 “太康
80多個國家爭先搶購 “太康  全國各地樓市調控已60余次
全國各地樓市調控已60余次  哈爾濱一滑雪場纜車系統發生
哈爾濱一滑雪場纜車系統發生  農村農業部:建立和完善蔬菜
農村農業部:建立和完善蔬菜 -
 小果莊人撤了動物咋辦?他們
小果莊人撤了動物咋辦?他們  2021中國長春(國際)無人駕駛
2021中國長春(國際)無人駕駛  2020年北京薪酬大數據報告:
2020年北京薪酬大數據報告:  中國地震臺網:四川宜賓市珙
中國地震臺網:四川宜賓市珙  創歷史新高!國家郵政局:
創歷史新高!國家郵政局: 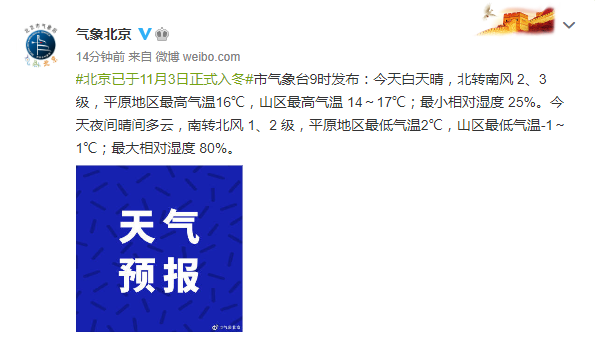 北京于11月3日正式邁入冬季
北京于11月3日正式邁入冬季 -
 中國地震臺網:新疆伊犁州鞏
中國地震臺網:新疆伊犁州鞏  進博會:共享經濟遍地開花
進博會:共享經濟遍地開花  中國易地扶貧搬遷960余萬人
中國易地扶貧搬遷960余萬人  甘肅靖遠移民農戶:搬遷地不
甘肅靖遠移民農戶:搬遷地不  重慶巫溪寧廠鎮:來自一個千
重慶巫溪寧廠鎮:來自一個千  馬鞍山綜合保稅區:前三季度
馬鞍山綜合保稅區:前三季度
金融




財經






要聞
公司

綠田機械股份有限公司(簡稱綠田機械)將于2021年3月18日首發上會。綠田機械擬在上交所主板上市,本次公開發行股份數量不超過2200萬股,占發
詳細>>
11月6日,國際數據公司(IDC)手機季度跟蹤報告顯示,2020年第三季度中國智能手機市場出貨量約8480萬臺,同比下滑14 3%。出貨量前五的品牌分
詳細>>
突如其來的疫情黑天鵝,讓中國零售行業整體遇冷,增長一度陷入停滯。對于業務模式主要面向線下門店的內衣企業來說,更是遭遇了前所未有的危
詳細>>
2020年上市公司半年報披露已結束,然而,神州數碼今年上半年的業績并不理想,營收凈利雙雙下滑。并且近日公司發布公告稱,10大董事、高管擬
詳細>>
8月28日,兌吧發布了2020年中期業績。盡管受疫情及宏觀經濟影響,其廣告收入有所下滑同時導致經調整凈利潤亦由盈轉虧,但是其SaaS業務表現
詳細>>
27日晚間,申通快遞發布2020年半年報。數據顯示,上半年,公司實現營業收入92 58億元,同比下降6 21%;實現歸屬于上市公司股東的凈利潤7067
詳細>>